石油价格预测时间序列模型应用_石油走向预测
1.如何计算线性回归模型的代价函数
2.国际石油市场风险度量及其溢出效应检验方法
3.谁有The Information Content of Annual Earning Announcements的全文翻译?
4.中心数据库设计
5.能源经济学的研究方向
6.齐齐哈尔市地下水水质评价与污染预警

一、手工会计信息系统(15世纪~至今)
其核心是会计恒等式、会计循环、会计科目表、分录和账簿。该模式可追溯到13、14世纪商人的借贷记账法,后由意大利数学家、近代会计之父卢卡·帕乔利经过6年调查研究和整理,于1494年11月10日出版了《数学大全》一书。该书共分5部分:(1)算术和代数;(2)商业算术的应用;(3)簿记;(4)货币和兑换;(5)纯粹和应用几何。其中,论述复式簿记的是第3卷第9部第11篇《计算与记录详论》①。它是人类历史上关于复式簿记的最早文献,标志着近代会计的开始。该模式一直延用至今。其缺点是:处理会计数据易出错、效率低、信息孤岛、丢掉了非财务信息。
二、电算化会计信息系统(20世纪50年代~至今)
电子计算机应用于手工会计信息系统之中,即为电算化会计信息系统模式,该模式正逐步取代手工会计信息系统。1946年2月14日,由美国和宾夕法尼亚大学合作开发的世界上第一台电子计算机ENIAC在费城公诸于世。1954年美国通用电气公司第一次使用计算机计算职工工资,从而引起了会计处理的变革,标志着电算化会计信息系统模式的开始。电算化会计信息系统横向扩展,最后形成整个企业管理信息系统,纵向发展并按职能结构可分为“会计信息处理系统、会计管理信息系统、会计决策支持系统”②。
1.会计信息处理系统(AIPS ,Accounting Information Processing System)
又称会计核算信息系统或财务会计电算化,其中包括财务系统:总账、报表、工资、固定资产、成本、存货核算、应收账款、应付账款、财务分析等;还包括业务系统:购、库存、销售。AIPS处于成熟应用阶段,目前相关研究重点是电子商务和ERP。
(1)电子商务。20世纪80年代EDI(电子数据交换)得到发展,90年代以后基于Internet的电子商务也得到广泛应用,他们的特点是改变了业务系统中询价、购、支付、销售、配送等指令的处理平台,不但迅速快捷,而且基于网上的这些业务活动会被自动集,自动生成财务数据,企业对外实时报告也成为可能。
(2)ERP。企业ERP的概念产生于20世纪90年代初,由美国加特纳公司(Gartner Group Inc.)提出。AIPS相当于ERP中的会计子系统,但二者产生的途径不同,这是由于不同的企业,出于技术和管理水平的限制,取两种不同的循序渐进的道路进行信息系统建设所致的:一是,部分企业从使用易学易用的AIPS开始,再扩展到生产制造、客户关系管理,过渡到面向供应链管理的ERP,典型的软件产品是中国的用友、金蝶等;二是,部分企业走MRP、MRPII、ERP的开发应用之路,典型的软件产品是北京利玛、德国SAP R/3等。制造MRPII的概念起源于17年9月,由美国生产管理专家怀特提出,MRPII “主要侧重对企业内部人、财、物等的管理”,其软件功能相当于AIPS系统加上生产制造系统(含物料需求MRP)。ERP在MRPII基础上扩展了管理范围,把供应商的制造、企业内部的制造活动、客户需求整合在一起,形成企业一个完整的供应链,并对供应链上所有环节如、购、库存、生产制造、分销、财务、运输、人事管理、质量控制、产品数据等进行有效管理。第二种途径应该是信息系统建设的主流途径,因为它符合首先应记录发生的经济业务、再由业务信息自动生成会计信息的自然流程。
2.会计管理信息系统(AMIS, Accounting Management Information System)
又称管理会计电算化,它以计算机为工具,利用AIPS提供的会计核算数据,运用统计学、计量经济学、运筹学等数学模型,建立各种会计管理模型,进行会计管理。例如,利用时间序列或回归分析方法进行成本性态分析、成本预测、销售预测;利用边际分析、线性规划、概率统计等方法进行本量利分析,进行生产品种和数量决策、定价决策、经济订货量决策;筹资及最佳货币持有量决策、长期投资决策和敏感性分析等。20世纪50年代,计算机在经济订货量等库存管理模型中的应用,标志着AMIS应用的开始,应用效果主要取决于领导者重视程度和会计人员知识结构等因素。有人也将AMIS划分在会计决策支持系统ADSS中。
3.会计决策支持系统(ADSS,Accounting Decision Support System )
决策支持系统,是指利用数据和模型帮助决策者去解决半结构化、非结构化问题的交互式计算机系统。DSS主要分为:传统决策支持系统、智能决策支持系统、新决策支持系统和综合决策支持系统几种。
(1)传统决策支持系统。20世纪70年代初,美国人莫顿(Morton)在《管理决策系统》一文中首先提出DSS的概念,并在20世纪80年代得以迅速发展。传统决策支持系统,实质上是管理信息系统提供的数据库和运筹学提供的模型库相结合的产物,决策者进行定量分析。
(2)智能决策支持系统。专家系统(ES,Expert System)兴起于20世纪60年代末,并于20世纪80年代得到了广泛发展,其核心由推理机、知识库和数据库组成,它利用专家知识、推理的方法,像人类专家一样解决特定领域的实际问题。ES与传统的DSS几乎同时兴起,并各自平行发展起来,ES决策者进行定性分析。20世纪90年代初,传统决策支持系统与专家系统相结合,形成了集定量分析、定性分析于一身的智能决策支持系统,提高了决策能力。
(3)新决策支持系统。20世纪90年代中期,兴起了三种互相独立又相互关联的决策支持新技术,即数据仓库(DW,Data Warehouse)、联机分析系统(OLAP,On Line Analytical Processing)、数据挖掘(DM,Data Mining)。DW、OLAP、DM相组合,就形成了新决策支持系统,包括基于数据仓库的DSS;基于数据仓库和联机分析系统的DSS;基于数据仓库、联机分析系统和数据挖掘的DSS。
数据仓库是一个面向主题的、集成的、稳定的、反映历史变化的数据集合。不同于普通数据库的事物处理,数据仓库是一种存储技术,侧重于存储和管理面向决策主题的数据,用于决策分析。它将数据库的数据按决策需要重新组织存储,包含大量历史、当前、综合数据,为用户提供决策的随机查询、综合数据、随时间变化的趋势分析信息等。联机分析系统,侧重于把数据仓库中的数据进行多维分析,如切片、钻取、旋转等,并转换成决策信息。数据挖掘,是使用统计、神经网络、机器学习等方法,对数据仓库或数据库中的数据进行挖掘分析,从中提取隐含的、以前未知的有用信息并用它来进行决策。数据挖掘广泛应用于商业、银行、电信、统计局、地质勘探、税务等部门。
(4)综合决策支持系统。把数据仓库、联机分析系统、数据挖掘、数据库、模型库、专家系统结合起来,就形成了综合决策支持系统。
(5)会计决策支持系统ADSS 。ADSS是DSS在会计领域的应用。AMIS可归入ADSS中,除了AMIS之外,还有财务状况分析专家系统,例如美国人理查德·希克斯和罗纳德·李开发的VP专家系统、北京用友通宝公司的《用友通宝财务报表分析专家系统》。还有审计决策支持系统,例如美国的NAARS系统,可以指导审计人员如何形成审计观点;例如珠海中普公司的计算机审计软件《中岳通用审计系统》,运用计量经济学方法建立财务数据的数学模型,由系统从数据的突变点直接找出可能存在的疑点,使得疑点分析及查证功能具有智能化,确定审计重点。还有审计专家系统,它可以评价内部控制的分析检查的结果,判断内部控制的强弱,给出实质性测试的范围、重点,提高审计效率、降低审计风险。另外,沃尔玛利用数据挖掘工具研究销售数据仓库,以分析顾客的购买习惯。也有人尝试在审计和实证会计研究中使用数据挖掘。
4.电算化会计信息系统的弊端
电算化会计信息系统的弊端主要表现为:(1) 尽管提高了工作效率,但它仍是手工会计系统的翻版,核心仍然是会计科目表、分录、账簿。即使是ERP,其中的会计子系统仍保留了人工会计的特质;(2)系统仅记录了组织中的部分业务,即仅记录了影响组织资产、负债、所有者权益变动的会计事项,忽略了许多业务细节;(3)系统仅记录了会计事项的部分数据,即会计事项的货币计量结果,丢掉了许多非财务信息;(4)系统严重依赖于会计科目表,只按照会计科目表来组织数据以编制会计报表,用户不能从多个角度探究、分析会计事项的货币计量结果。另外,会计科目表给系统的维护也带来了困难,修改科目表影响信息的记录、过账、结账、试算平衡,也影响前后期会计数据的一致性;(5)提供的会计报表不实时,缺乏时效性。报表信息过于综合,既不能满足用户的个性化需要,也使许多用户不易理解,使用效果受到限制;(6)会计系统与其他业务部门的系统数据存储重复,造成冗余甚至不一致,特有的借贷记账法也是造成数据不一致的原因。
针对上述弊端,人们探寻了新的会计信息系统模式,本文将其划分为准现代会计信息系统和现代会计信息系统。
三、准现代会计信息系统(20世纪60年代末~至今)
1. 事项会计(Event Accounting)
现行财务会计是价值法,会计信息主要属于价值信息,并通过通用报表将信息传递给使用者。1969年美国会计学家索特发表了《构建基本会计理论的事项法》一文,全面阐述了以事项法(Event Approach)为基础所形成的基本会计理论。所谓事项是指可观察的、可以用会计数据来表现其特征的具体活动、交易和。事项法认为,会计的目标在于提供与各种可能决策模型相关的、不经过加工汇总的原始事项,由使用者从中选择并在自己的决策模型运用。因为,一套通用的价值信息并不能满足所有使用者的决策需要、加工后的价值信息可能失真、单一货币计量丢掉了非财务信息。因此会计事项信息系统应具有强大的数据库,包含大量基础数据以反映组织活动的全部事项,事项具有的多重属性会计都要反映,而不只局限于价值量。
事项会计的思想,理论上克服了电算化会计信息系统中的诸多弊端,但由于缺乏可操作性,不得以它仍然要记录会计分录,主张重构会计报表以方便从会计报表演绎出相关事项,获取更多的决策信息。由于未能摆脱会计科目表、分录等核心内容,因此本文称其为准现代会计信息系统。
2. 数据库会计
计算机数据管理技术经历了人工管理(1946~20世纪50年代中期)、文件系统(20世纪50年代后期~20世纪60年代中期)、数据库系统(20世纪60年代后期)三个阶段。数据库系统又经历了第一代网状、层状系统(1969-),第二代关系数据库系统(10-),第三代以面向对象模型为主要特征的数据库系统(1990-)。
数据库会计的理论模型可以追溯到1939年,由戈茨(Goetz)提出,该系统是保存最原始状态的数据,以便数据可以按照最切合每一个用户需求的形式进行组织。20世纪60年代末数据库系统产生后,许多学者,包括Colantoni(11)、Liebarman(15)、Everest(17)等人,尝试将数据库技术应用于该理论模型,建立储存强大的、分解的、多计量属性数据的会计信息系统。遗憾的是,在建立数据模型时,主要按传统会计模式的数据逻辑模型组织数据,利用数据库技术对数据进行更多的分类操作;只描述与复式记账会计体系有关的数据,未能用先进的数据结构描述会计处理的对象本身,以便系统能产生更多的视图。因此,本文也将其称为准现代会计信息系统。
四、现代会计信息系统(1982年~至今)
1982年7月,美国密歇根州立大学会计系教授麦卡锡(McCarthy)在《会计评论》上发表了题为《REA会计模型:共享数据环境中的会计系统的一般框架》的论文,提出了REA模型,标志着现代会计信息系统模式的开始。REA表示(Resources)、(Events)、参与者(Agents),后来加入了地点(Location),变成了REAL模型。REAL是以业务流程重组为基础或前提的驱动处理模式,它集业务(例如购订货、验收材料、支付货款),以及涉及的(例如材料、现金)、参与者(例如公司职员、供应商、银行)、发生时间和地点等原始的未经处理的详细数据,存放于包含表、表、参与者表和地点表的集成数据库中,通过报告工具生成用户所需的视图,包括财务信息和非财务信息,输出可以是固定格式的,也可以由用户自己定义。系统中可以不再有日记账、分类账、会计科目、分录等元素。
随着数据库、网络技术的发展,尤其是20世纪90年代REAL模式在美国学术界、实务界受到相当关注。1994年Denna 和Jasperson对、钢铁和石油生产过程用REAL建模;19年Geers和McCarthy把REAL应用于供应链和工作流任务数据建模也获得成功;1994年IBM公司用REAL原理开发了IBM工资系统;普华永道会计师事务所19年对REAL模式作一定折中后建立了在大型数据库中迅速获取数据的Geneva系统。虽然实务中仍有问题有待研究,例如数据存储量大、通用与用户化视图的生成问题、与传统会计准则冲突等问题。但REAL模式是理论最完善、研究最系统、变革力度最大、成果最多的一种创新模式,极有可能成为未来会计信息系统的主流模式。
REAL的核心是集成,集成业务处理、信息处理、实时控制和管理决策。它不仅仅局限于财务管理,而是面向整个企业管理,从详细记录最原始经济业务的属性或语义表述于数据库中开始,而不是从记录经过人为加工后的会计分录开始,其基本元素不再是科目、分录、账簿。充分利用信息技术并克服了电算化会计信息系统的弊端,因此称其为现代会计信息系统。
如何计算线性回归模型的代价函数
概率论与数理统计不需要高数基础,但是有高数基础的话,学起来会轻松一点。
概率论与数理统计是数学的一个有特色且又十分活跃的分支,一方面,它有别开生面的研究课题,有自己独特的概念和方法,内容丰富,结果深刻;另一方面,它与其他学科又有紧密的联系,是近代数学的重要组成部分。
概率论与数理统计的理论与方法已广泛应用于工业、农业、军事和科学技术中,如预测和滤波应用于空间技术和自动控制,时间序列分析应用于石油勘测和经济管理,同时又向基础学科、工科学科渗透,与其他学科相结合发展成为边缘学科,这是概率论与数理统计发展的一个新趋势。
题型总结
目前,大部分同学开始了概率论和数理统计的复习,本文主要想对同学们近期的复习做一个简单的指导。概率论与数理统计初步主要考查考生对研究随机现象规律性的基本概念、基本理论和基本方法的理解,以及运用概率统计方法分析和解决实际问题的能力。
国际石油市场风险度量及其溢出效应检验方法
没有具体数据要求,一般来说,数据越多越好。
通过线性回归算法,我们可能会得到很多的线性回归模型,但是不同的模型对于数据的拟合或者是描述能力是不一样的。我们的目的最终是需要找到一个能够最精确地描述数据之间关系的线性回归模型。这是就需要用到代价函数。
代价函数就是用来描述线性回归模型与正式数据之前的差异。如果完全没有差异,则说明此线性回归模型完全描述数据之前的关系。
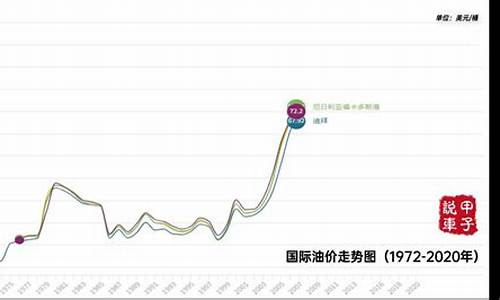
一条趋势线代表着时间序列数据的长期走势。它告诉我们一组特定数据(如GDP、石油价格和股票价格)是否在一段时期内增长或下降。虽然我们可以用肉眼观察数据点在坐标系的位置大体画出趋势线,更恰当的方法是利用线性回归计算出趋势线的位置和斜率。
谁有The Information Content of Annual Earning Announcements的全文翻译?
4.4.1.1 基于GED分布的GARCH-VaR模型
在对油价收益率序列建模时,往往发现收益率的波动具有集聚性。为了刻画时间序列的波动集聚性,Engle(1982)提出了ARCH 模型。而在ARCH 模型的阶数很高时,Bollerslev(1986)提出用广义的ARCH 模型即GARCH 模型来描述波动集聚性。
GARCH模型的形式为
国外油气与矿产利用风险评价与决策支持技术
式中:Yt为油价收益率;Xt为由解释变量构成的列向量;β为系数列向量。
国外油气与矿产利用风险评价与决策支持技术
事实上,GARCH(p,q)模型等价于ARCH(p)模型趋于无穷大时的情况,但待估参数却大为减少,因此使用起来更加方便而有效。
同时,由于油价收益率序列的波动通常存在杠杆效应,即收益率上涨和下跌导致的序列波动程度不对称,为此本节引入TGARCH模型来描述这种现象。TGARCH模型最先由Zakoian(1994)提出,其条件方差为
国外油气与矿产利用风险评价与决策支持技术
式中:dt-1为名义变量:εt-1﹤0,dt-1=1;否则,dt-1=0,其他参数的约束与GARCH模型相同。
由于引入了dt-1,因此油价收益率上涨信息(εt-1﹥0)和下跌信息(εt-1﹤0)对条件方差的作用效果出现了差异。上涨时, 其影响程度可用系数 表示;而下跌时的影响程度为 。简言之,若Ψ≠0,则表示信息作用是非对称的。
在关注石油市场的波动集聚性及杠杆效应的基础之上,进一步计算和监控石油市场的极端风险同样是非常重要的。而监控极端市场风险及其溢出效应的关键在于如何度量风险,为此,本节将引入简便而有效的VaR 方法。VaR(Value-at-Risk)经常称为风险值或在险值,表示在一定的持有期内,一定的置信度下可能的最大损失。VaR 要回答这样的问题:在给定时期内,有x%的可能性,最大的损失是多少?
从统计意义上讲,VaR表示序列分布函数的分位数。本节用国际油价收益率的分布函数的左分位数来度量油价下跌的风险,表示由于油价大幅度下跌而导致的石油生产者销售收入的减少;而用分布函数的右分位数来度量油价上涨的风险,表示油价大幅度上涨而导致的石油购者的额外支出。这种思路,一方面推进了一般金融市场仅仅分析价格下跌风险的做法;另一方面,也针对石油市场的特殊情况,更加全面地度量了市场风险,从而为从整体上认识石油市场,判断市场收益率的未来走向奠定了基础。
VaR风险值的计算方法很多,能够适用于不同的市场条件、数据水平和精度要求。概括而言,可以归结为3种:方差-协方差方法、历史模拟方法和方法。本节用方差-协方差方法计算国际石油市场的VaR 风险。在用方差-协方差方法的过程中,估计VaR模型的参数是至关重要的。常用的参数估计方法包括GARCH 模型和J.P.摩根的Risk Metrics方法。由于后者设价格序列服从独立异方差的正态分布,而且不能细致描述价格波动的某些特征(如杠杆效应),因此相对而言,前者更受青睐。但是,使用GARCH模型估计VaR时,选择残差项的分布是一个非常重要的问题。考虑到油价收益率序列具有尖峰厚尾和非正态分布的特征,因此直接用正态分布的设往往会低估风险。为此,本节引入Nelson(1990)提出的广义误差分布(GED)来估计GARCH模型的残差项。其概率密度函数为
国外油气与矿产利用风险评价与决策支持技术
式中: Г(·)为gamma函数;k为GED分布参数,也称作自由度,它控制着分布尾部的薄厚程度,k=2表示GED分布退化为标准正态分布;k﹥2表示尾部比正态分布更薄;而k﹤2表示尾部比正态分布更厚。可见GED分布是一种复杂而综合的分布。实际上,也正是由于GED分布在描述油价收益率分布的厚尾方面具有独特的优势,因此本节引入基于GED分布的GARCH模型来估计国际石油市场收益率上涨和下跌时的VaR。
计算出石油市场的VaR风险值之后,为了给有关方面提供准确可靠的决策支持,有必要对计算结果进行检验,以判断所建立的VaR模型是否充分估计了市场的实际风险。为此,本节将用Kupiec提出的检验方法来检验VaR模型的充分性和可靠性。该方法的核心思想是:设计算VaR的置信度为1-α,样本容量为T,而失效天数为Ⅳ,则失效频率f=Ⅳ/T。这样对VaR 模型准确性的评估就转化为检验失效频率f是否显著不同于α。基于这种思想,Kupiec提出了对原设f=а的最合适的似然比率检验:在原设下,统计量LR服从自由度为1的X2分布,95%和99%置信度下的临界值分别为3.84和6.64。根据x2分布的定义,如果估计值LR大于临界值,就拒绝原设,即认为估计的VaR模型是不充分的。
国外油气与矿产利用风险评价与决策支持技术
4.4.1.2 基于核权函数的风险溢出效应检验方法
本节将用Hong(2003)提出的风险-Granger因果关系检验方法检验WTI和Brent原油市场的风险溢出效应。该方法的核心思想是通过VaR 建模来刻画随着时间变化的极端风险,然后运用Granger因果检验的思想来检验一个市场的大风险历史信息是否有助于预测另一个市场的大风险的发生。
首先,定义基于VaR的风险指标函数。以下跌风险为例:
Zm,t=I(Ym,t﹤-VaRm,t)(m=1,2) (4.11)
式中:I(·)为指标函数。当实际损失超过VaR时,风险指标函数取值为1,否则为0。
如果检验市场2是否对市场1产生了单向的风险溢出,则原设为H0:E(Z1,t∣I1,t-1)=E(Z1,t∣It-1),而备择设为HA:E(Z1,t∣I1,t-1)≠E(Z1,t∣It-1),其中It-1={Ym,t-1,Ym,t-2,…),表示t-1时刻可以获得的信息集。通过这种转换,{ Y1,t}和{Y2,t}之间的风险-Granger因果关系就可以看成是{Z1,t}和{Z2,t}之间的均值-Granger因果关系,即计量经济学模型中广泛使用的Granger因果关系。
如果Ho成立,即市场2 对市场1不存在单向的风险-Granger因果关系,则表示Cov(Z1,t,Z2,t-j)=0, j﹥0。如果对某一阶j﹥0,有Cov(Z1,t,Z2,t-j)≠0,则表明存在风险-G ranger因果关系。换言之,当一个市场发生大的风险时,我们能用这个信息去预测另一个市场未来可能发生同样风险的可能性。
现在设VaRm,t=VaRm(Im,t-1,α),m=1,2是市场m在风险水平(即显著性水平)α下得到的VaR序列,本节引入基于GED分布的GARCH 模型,并利用方差-协方差方法得到该序列。设有T个随机样本 并令Zm,t=I(Ym,t﹤-VaRm,t),m=1,2,则定义Z1,t和Z2,t之间的样本互协方差函数(CCF)为
国外油气与矿产利用风险评价与决策支持技术
式中: 。而Z1,t和Z2,t的样本互相关函数为
国外油气与矿产利用风险评价与决策支持技术
式中: 是Zm,t的样本方差;j=0,±1,…,±(T-1)。
然后,Hong(2003)提出了基于核权函数的单向风险-Granger因果关系检验统计量:
国外油气与矿产利用风险评价与决策支持技术
式中:中心因子和尺度因子分别为
国外油气与矿产利用风险评价与决策支持技术
式中k(·)为核权函数,而且H ong(2003)证明了Daniell核权函数k(z)=sin(π)z/π ,z∈(-∞,+∞)是最优的核权函数,能够最大化检验效力。该核权函数的定义域是无界的,此时可把M 看作是有效滞后截尾阶数;而且当M 较大时,Q1(M)能够更加有效地检测出风险溢出效应的时滞现象。
Hong(2003)同时给出了检验双向风险-Granger因果关系的统计量,其原设为两个市场之间任何一个市场均不G ranger-引起另一个市场的极端风险,并且两个市场之间不存在任何即时风险溢出效应。这表示对于任意阶j=0,±1,±2,…,均有Cov(Z1,t,Z2,t-j)=0。为了检验该原设,Hong(2003)提出了如下的统计量:
国外油气与矿产利用风险评价与决策支持技术
式中:中心因子和尺度因子分别为
国外油气与矿产利用风险评价与决策支持技术
原设成立时,Q1(M)和Q2(M)在大样本条件下均服从渐近的标准正态分布。而且,Hong(2003)指出,运用这两个统计量时,应该使用标准正态分布的右侧临界值。
中心数据库设计
第5章
决策有用性的信息观
财务会计理论
5.1 概述
俗话说:“布丁好不好,尝过就知道”。从一般意义上讲,如果有效市场理论和基于它的决策 理论是对现实的合理描述,那么我们就应注意到证券市场价值对新信息做出的预测性的反应。
这导致了会计上的实证研究。尽管我们难以设计实验来检验决策有用性的影响,但会计研究 已经证实了,证券的市场价格确实并且至少能对会计信息中的净收益做出反应。对此,鲍尔和布 朗(Ball and Brown)于1968年首次提供了可靠的证据。随后,人们对证券市场反应的其他方面也进 行了大量的实证研究。
根据这些研究,会计信息可以帮助投资者估计证券报酬的期望值与风险,并且似乎确实对他 们有用。投资者只要考虑例 3-1 中贝叶斯理论的运用,便会发现,如果会计信息没有信息含量, 那么,人们在获取此信息后将不会改变其信念,因而就不会产生买卖决策。没有买卖决策,价格 也就不会发生变化。实质上,只有当信息能改变投资者的信念和行为时,它才是有用的信息。而 且,信息的有用程度可以通过其公布后所导致的价格变化程度来衡量。
这种把有用性等同于信息含量,被称之为财务报告的信息观 ,它是一种从 1968年起就在财务 会计理论和研究中占统治地位的方法。正如 3.8节和 4.8节所论述的那样,它已被主要的会计准则 制定组织所纳。该观点认为,投资者希望对未来证券报酬做出自已的预测(而不是让会计人员 在理想条件下替他们做预测),并“吸收”这方面的所有有用信息。正如前面提到的,实证研究 已经表明,至少有部分会计信息被认为是有用的。而且,该观点还指出,通过市场的反映以及相 应的实证研究,这样可以引导会计人员把握投资者重视和不重视的信息,从而帮助他们进一步提 高信息的有用性。
然而,在将有用性等同于证券价格变化程度时必须注意,这并不是意味着,只要会计人员能 根据市场对信息的反应来决定所要提供的财务报表信息,社会状况就一定会较好。因为,信息是 一种非常复杂的商品,它的个体价值和社会价值是不同的,其中一个原因就是成本。财务报表使 用者一般不需要为使用这些信息而直接支付费用,结果,即使社会成本(即公司产生和报告这些 信息所导致的成本,以提高产品价格的方式体现出来)高于所增加的有用性价值,他们仍然可能 发现信息是有用的。而且,信息对人们的影响是不同的,需要进行复杂的成本—效益权衡来协调 不同团体间的利益冲突。
当然,这样从全社会角度进行的考虑,并没有使信息观失效。会计人员仍然可以通过提供有 用的信息来努力提高自已在信息市场中的竞争地位。而且,如果证券价格能为投资机会提供好的 指示器做用,那么证券市场将会更加有效。然而,会计人员并不能宣称,那些能够产生最大市场 反应的会计政策便是“最好的”。
5.2 研究问题的概要
5.2.1 市场反应的原因
我们首先回顾一下为什么我们要预测公司的股票市场价格会对财务报表信息做出反应。在本 章的大部分内容中我们将把财务报表信息限定在报告净收益上。净收益的信息含量已经成为广泛 的实证研究的主题。财务报表其余部分的信息含量将在第 5.8节和第 6章进行讨论。
考虑下面的一些预测,它们是关于投资者行为对财务报表信息所做反应的预测:
决策有用性的信息观
第5章
1. 投资者对公司股票的期望报酬和风险有一些先验概念。这些先验概念是基于包括市场价格
在内的公司的当期净收益公布之前所有公开可利用的信息。即使这些先验概念是基于公开的可利 用信息之上的,但它们并不需要完全一样,这是因为投资者所获得的信息量和解释所获得信息的 能力是不同的。这些先入之见也可能包括对公司现在和未来盈利能力的期望,因为证券的未来收 益至少将部分依赖于盈利能力。
2. 在当年净收益公布之后,一定投资者将会通过分析收益值从而获得更多的信息。例如,如 果出现高的净收益,或高于所期望的净收益,这便是利好消息。根据贝叶斯理论,一些投资者将 会增强他们对未来盈利能力和报酬的信心。另外那些对当期净收益有着更高期望的投资者,则会 将同样的净收益值解释为利空消息。
3. 投资者若对未来盈利能力和报酬的信心有所增强,他将愿意以当前的市场价格买入公司股 票,反之亦然(这也可能改变他们对这些股票的风险估计)。
4. 我们期望将观察到,在公司公布其净收益后不久股票成交量会放大。此外,投资者的先验 概念和他们对当期财务信息的解释的差异越大,成交量就越大。如果把报告净收益解释为利好消 息的投资者多于解释为利空消息的投资者,我们期望将看到该公司股票的市场价格会上涨。反之 亦然。
1968年比弗在经典研究中验证了成交量的反应。他发现在盈利公布的那个星期成交量呈戏剧 性的增加。比弗的有关发现将在本章的第 8个问答题中做进一步详述。在本章后面部分,我们将 集中讨论市场价格的反应。市场价格反应与成交量反应相比,前者对决策有用性提供了更为有力 的检验,因为我们可以利用更好的模型来预测价格反应,例如资本资产定价模型( CAPM)(4.3 节)。而利用成交量则难以清晰地进行精确的预测。
你将看到前述的预测是紧扣第 3章、第 4章的决策理论和有效市场理论的。如果这些理论与会 计人员有关联,那么他们的预测将从实证研究中得到证实。正如这些理论让我们所相信的那样, 实证研究人员可以通过取得公布年报的公司的样本,并研究在盈利公布时成交量和价格是否对利 好或利空消息做出反应,从而对所做的预测进行检验。
然而,基于许多原因,这并不像看起来那样简单。
5.2.2 寻找市场反应
1. 有效市场理论意味着市场将对新的信息做出快速反应。因此,知道当年的报告净收益首次 在何时公布是很重要的。如果研究人员在几天以后再去寻找对成交量和价格的影响,那么,即使 影响确实存在也可能观察不到。
通过利用金融媒体如《华尔街日报》报道的公司净收益的日期,研究人员已经解决了这个问 题。如果有效市场发生做用,那么在该日期前后几天内的狭小窗口 里,将会存在这种反应。
2. 报告净收益被评价为利好消息还是利空消息,是相对于投资者的期望值而言的。如果一家 公司报告净收益,比如说是 200万美元,刚好是投资者所期望的(比如说通过季度报告、公司领 导的演讲、分析家的预测或者也许是来自管理当局讨论分析书 (MD&A)的有前瞻性的信息和预 测),那么该报告净收益几乎没有什么信息含量。因为,投资者已经根据较早的信息改变了其信 念。然而,如果投资者期望净收益为 200万美元,而报告净收益为 300万美元,那么,情况就会完 全不同。这种利好消息将会使投资者迅速改变对公司未来前景的信念。
这意味着研究人员必须取得一个代表值,用来表示投资者的期望净收益。这可以用分析家们对季度或年度盈利的预测,或者通过设计公司过去的净收益的时间序列来估计期望净收益。一
个简单的模型是,令当年的期望净收益与上一年的相同。那么,净收益变化就代表它的非期望部 分。1987年布朗、格里芬、海格曼和泽米捷乌斯基 (Brown, Griffin, Hagerman and Zmijewski)在研 究一家预测组织的季度预测业绩时所提供的证据表明,分析家们的预测精度优于时间序列模型的 预测精度。另一种用于较早研究中的方案是,计算一个“会计 系数”,即估计一家公司的报告历 史净收益与所有公司的平均历史净收益之间的线性关系。若给定当年所有公司的平均净收益,则 该公司的期望净收益可根据线性关系估算出来。例如,如果过去 5年来某公司的净收益是所有公 司平均净收益的 1.2倍,且今年所有公司平均净收益为 100美元,那么该公司的期望净收益则为
120美元。
3. 在这里,总会发生许多影响公司股票的成交量和价格。这意味着市场对报告净收益的 反应是很难被发现的。例如,设某公司公布它的当年净收益,包含利好消息,同一天联邦 首次宣布赤字有大量增加。这一消息可能影响市场上所有或大部分证券的价格,这可能反过来掩 盖了该公司公布盈利的影响。因此,把这些影响股票报酬的因素分开是合乎需要的。
5.2.3 分离系统因素和特定公司因素
正如第 4.3节所叙述的,市场模型广泛用于分离对证券报酬产生影响的系统因素和特定公司 因素。图 5-1给出了第 t期第 j个公司市场模型的图示,这里,我们设期间为 1天。研究人员有时 也使用更长的期间,如一周、一个月或一年,甚至也可以是更短的期间。
图5-1说明了j公司股票收益与市场投资组合 (例如以道琼斯指数为代表 )之间的关系。
实际报酬0.001 5
(非正常报酬)=
期望报酬0.000 9
0.000 6
斜率=
=0.80
截距0.000 1
R =t期市场投资组合报酬
R =t期公司股票报酬
图5-1 用市场模型分离系统和特定证券报酬
图5-1描述了第 4.3节中的市场模型:
决策有用性的信息观
第5章
R = + R +
jt j
j Mt jt
正如第 4.3节所叙述的那样,研究人员将获取 R 和R
的历史数据,使用回归分析方法来估计
模型的系数。这里设
=0.000 1和
=0.80,如图 5-1所示[1]。
在《华尔街日报》查阅当期盈利的宣布日期后,现在研究人员可以根据 j 公司的市场模型进 行估计。我们把这一宣布日期叫做“第 0天”。设第 0天道琼斯指数报酬为 0.001[2]。那么根据 j公 司的估计市场模型便可预测它在这一天的股票报酬。如图 5-1所示,它的期望报酬为 0.000 9 [3]。现 在设 j公司第 0天的股票实际报酬为 0.001 5 ,于是实际与期望的报酬之间的差额为 0.000 6 (即这
=0.000 6)。这里的 0.000 6是那一天 j公司股票的非正常(也叫非期望或特定公司)报酬的估
计值 [4]。这一非常收益也可以解释为第 0天j公司股票扣除系统因素后的股票报酬率。请注意,这 种解释与例 3-3 是一致的,在那里,我们把影响股票报酬的因素分为系统因素和特定公司因素。 目前的程序为这一区分提供了一种可操做的方法。
5.2.4 报酬与收益的比较
现在,实证研究人员可以把前面计算出来的第 0天的股票非正常报酬,和该公司当期报告净 收益的非期望部分进行比较。如果非期望净收益是利好消息(即正的非期望净收益),那么,在 有效证券市场条件下便会出现正的股票非正常报酬,这证明,在一般意义上,投资者对盈利的非 期望利好消息做出了顺利的反应。若当期盈利宣布是利空消息,则相似的推理方法同样适用。
为了提高研究的功效,研究人员也许希望同样地比较第 0天前后几天的情况。例如,有效市 场有可能提早一两天获悉利好或利空的盈利消息。相反地,当市场在消化信息时,尽管有效市场 表明任何超额报酬都会很快消失,但正的或负的股票非正常报酬还是有可能延续一两天。因此, 总合第 0天前后的三五天狭小窗口内的股票非正常报酬,似乎比仅验证第 0天的来得更为合理。同 时,这也可防止当期盈利在金融媒体上公布的日期与该信息公开可利用的日期不一致的可能性。
如果对利好或利空消息,某一公司的样本群产生了相应的正负股票非正常报酬,那么,研究 人员就可能得出结论,这支持了基于决策理论和有效市场理论的预测。而这也将反过来支持财务 会计报告的决策有用性方法,因为,如果投资者没有发现报告净收益信息是有用的,那么市场反 应将无法被观测到。
当然这种方法不是十分简单的,其中使用了许多设和估计。一种复杂情况是公司盈利公布 时,其他的特定公司信息也纷纷随兴而至。例如,如果 j公司在公布当期盈利的同一天宣布股票分 割或改变它的股利,那么,我们将很难知道市场是对其中一个还是另一个因素做出反应。然而, 研究人员在处理这类问题时,可以简单地把这样的公司从样本中剔除出去。
另外一种复杂情况是对公司 值的估计,它需要像图 5-1那样把系统的股票报酬和特定公司的 股票报酬分开。正如所提到的,这种估计通常利用市场模型对历史数据进行回归分析而得到。那
么 估计值就是回归线的斜率。然而,公司的 值可能一直在变化,例如,就像公司营运或资本结 构变化一样。如果 估计值不等于真实的 值,这将影响对股票非正常报酬的计算,也就可能导致 研究结果的偏差。
有许多方法可以处理这种复杂情况。例如,可以用第二种观点,通过财务报表信息,而不 是市场数据,来估计 值(将在 5.7节讨论)。另外, 值也可从盈利公布后的期间估计,并与公布 前的估计值进行比较。这些简单步骤的基本原理是市场模型,它仅仅是一个模型,并不能保证充分描述产生股票报 酬的实际过程。同时,这里也存在许多可利用的市场投资组合报酬指数,道琼斯指数仅是其中之 一。应该选用哪一个呢?因此,由于构造模型和度量问题,在计算股票非正常报酬时,通过 进 行估计与通过控制风险进行消除,这两种方法相比前者可能会出现更大的误差 [5]。
布朗和沃纳 (Brow and Warner,1980)用模拟研究对这些问题进行过检验。尽管存在如前所述 的构造模型和度量问题,布朗和沃纳仍得出结论:对于月收益窗口,市场模型的程序(即 5.2.3节 描述的模型程序)比其他各种可选方案,表现得更加合理(这包括前面提到的两种)。因此,我 们将集中讨论这个模型程序。
使用市场模型的程序,我们的确可以看到,市场对盈利信息的反应与理论所预测的一样。我 们将回顾该反应的第一个有力证据,即著名的鲍尔和布朗于 1968年所得的研究。
5.3 鲍尔和布朗的研究
5.3.1 方法与结果
1968年鲍尔和布朗开创了会计上的资本市场实证研究的先河,这种研究一直持续到今天。他 们第一次以令人信服的科学证据提出,公司证券的市场价格会对财务报表的信息含量做出反应。 由于他们的基本方法现在仍在使用并得到拓展,所以值得对他们的论文作一简单回顾。他们的论 文不仅提供了一种范例性的指导,而且对那些希望更好理解财务报告决策有用性的人起到了鼓励 做用。
鲍尔和布朗以 1957年到 1965年9年间纽约证券( NYSE)261 家上市公司做为样本进行 检验。他们集中在盈利的信息含量上,排除了财务报表可能提供信息的其他部分,如流动性和资 本结构。其中原因之一是,正如前面所提,纽约证券的上市公司,一般在真正公布年报前 就已经在媒体上报道了其盈利,所以确定其信息为公众所利用的时点就相对比较简单。
鲍尔和布朗首先度量盈利的信息含量。他们的度量是很粗糙的,只是简单地把报告盈利分为 高于市场期望值(即利好消息)和低于市场期望值(即利空消息)两种。当然,这里需要知道市 场期望值的代表值。鲍尔和布朗使用了两种代表值。第一种代表值是基于 5.2.2节讨论过的 会计系数。他们是这样提出的:如果某公司以前年度的收益以某种独特的方式与其他公司的收益相关,根据它们的 历史相关关系和其他公司的当年收益,就可以得出该公司当期收益的条件期望值。 这样除了认可的影响外,当期收益所携带的新信息量可以用实际收益变化值与它的 条件期望值之间的差别来近似表示。(鲍尔和布朗的论文第 161页)
第二种代表值是设当期盈利的市场期望值等于上一年的实际盈利,即简单地认为非期望盈 利就是盈利的变化。这种简单时间序列方法的结果类似于使用会计 系数方法的结果。我们将把 注意力放在会计 系数方法上。
为了获得“历史相关关系的知识”,鲍尔和布朗研究了样本中各家公司 1957年前的数据。例 如,设在 1957年之前的几年里, j公司的平均盈利变化 [6]是样本中所有公司的盈利变化的 75 %。 同时设, 1957年样本中所有公司的平均盈利变化为 +100美元[7]。那么, 1957年j公司期望盈利变
决策有用性的信息观
第5章
化代表值为 +75美元。实际上,该程序设市场知道该历史相关关系,而且,市场很清楚在 1958
年以前,公司通常是怎样处理 1957年的各种盈利,并相应地调整 j公司的期望盈利值。现在设,
j公司在 1 9 5 8 年 2月份公布其 1 9 5 7年的盈利变化是 + 9 0 美元,超过了期望值,所以鲍尔和布朗把
1957年j公司归类为利好消息( GN)。对样本中所有公司从 1957年到1965 年进行同样的重复程序。 这样,样本中各公司公布的盈利均可相对于期望值归类为 GN或BN。
接下来,估计样本中各公司在盈利公布前后的股票市场报酬。这大部分是根据图 5-1 所示的 股票非正常报酬程序进行的。惟一的区别是鲍尔和布朗用的是股票月报酬( 1968年在计算机磁盘 上无法获得股票日报酬)。
类似于图 5-1,设 1958年2月纽约证券市场投资组合报酬为 0.001,得出 2月份的期望 报酬为 0.000 9。那么鲍尔和布朗将计算 j公司1958年2月的股票实际报酬,设为 0.0015,得到 2月 份的非正常报酬为 0.000 6 。由于 j公司1957年的盈利是在 1958年2月份公布的,而且它这个月的股 票报酬比市场多 0.000 6 。人们可能认为,之所以得到正的非正常报酬,是因为投资者顺利地对盈 利信息做出了反应。
问题是:“整个样本中都是这种模式吗?”答案是肯定的。如果我们考虑样本中所有利好消息盈利的公布(有 1 231 次),那么在公布盈利的那个月份里,正的平均证券市场非正常报酬将会
更为显著。相反地,样本中 1 109 次利空消息盈利的公布,导致了显著的负的平均非正常报酬。这 充分表明,证券市场在盈利公布前后一个月的狭小窗口内,确实对利好消息和利空消息做出反应。 在鲍尔和布朗的研究中,既有趣又重要的是,他们在计算证券市场非正常报酬时,宽大窗口 包括了盈利公布月份(第 0月)前 11个月和后 6个月。鲍尔和布朗计算了这 18个月宽大窗口中的每
月平均非正常报酬。其结果摘自鲍尔和布朗论文,如图 5-2所示。
图5-2中的变量 1用报告的净收益做为盈利指标,变量 2用每股盈利做为盈利指标,变量 3 用时间序列方法计算的每股期望盈利(变量 1和变量 2使用会计 系数方法)。可以看出,所有变 量给出了相同的结果。图 5-2的上半部分显示样本中发布利好消息的公司的累积平均非正常报酬, 下半部分显示的是公布利空消息的公司的累积平均非正常报酬。
5.3.2 因果关系与相关关系
请注意,图中的报酬是累积的。而且,正如前面所描述的,虽然在第 0月前后的狭小窗口内, 有大量的平均非正常报酬增加(由于利好消息)和减少(由于利空消息)。但是,市场在差不多 一年前就开始预计利好消息或利空消息。可以看出,如果一个投资者在公布利好消息一年之前买 入所有利好消息公司的股票,直到公布该消息的月底才卖出,那么可以获得比系统因素报酬高
7%的超额报酬。类似地,在公布利空消息前一年买入利空消息公司的投资组合股票,直到公布 利空消息才卖出,就会产生将近 9%的非正常损失 [8]。
这种较长时期的报酬表明,信息含量的宽大窗口和狭小窗口,对所进行的研究存在着重要的区
别。如果在盈利公布前后几天(或如鲍尔和布朗的研究中的一个月)的狭小窗口里,能观测到证券 市场对会计信息的反应,那么可以认为会计信息是市场反应的原因。因为在狭小窗口里,与净收益
相比,影响股票报酬的特定公司因素相对较少。而且,如果其他因素,如股票分割或股利宣布,确
实发生了,我们可以取前面提到的方法,把受影响的公司从样本中剔除出去。因此,在狭小窗口 下,证券报酬与会计信息之间的相关性说明,对投资者而言,会计披露是新信息的来源。
然而,在宽大窗口下估算报酬,会有许多其他因素影响。例如,某公司可能发现新的石油或天
然气储备,参加前景看好的研究开发( R&D),或者销售量和市场股票增加等。当市场通过 媒体或其他途径获悉这些信息时,由于证券价格具有提供部分信息的本性,股价将开始上涨。也就 是说,在一个有效市场中,证券价格将反映所有的可利用信息,而不仅仅是会计信息。因此,那些 经营确实不错的公司便通过有效市场抬高它们的股票价格,从而使股票的非正常报酬增加。
虽然以历史成本为基础计算的净收益在反映这类时滞后于市场,但当窗口扩大时,这种
滞后效果将会减弱。即在一段较长时期内,即使它们在初次被识别时存在滞后性,该期间内的报 告净收益也可捕获更多的如前所述的经济因素的影响。 1992年伊斯顿、哈瑞斯和奥尔森研究了这 一影响,他们发现当窗口扩大到十年时,证券报酬与以历史成本为基础计算的盈利之间的相关关 系增强。 1992年沃尔弗德和威尔德考察了类似的影响,发现证券报酬与年度报告期间的盈利之间 的相关关系,与季度报告期间的盈利之间的相关关系平均为 10倍以上。
虽然证券报酬与报告净收益之间的关系会因窗口的扩大而增强,但应该指出的是,我们不能 再认为报告净收益产生非正常报酬。至多只能说净收益与报酬是相关的。即两者都是与以公司经 济绩效为基础的实际情况正相关的。
因果关系和相关关系,两者的结果与具有信息含量的会计证据是一致的。从长远来看,不管 会计基础是什么,公司最后获得的报告总收益是一样的,而且,在一定限度内,将接近于理想条件(参考第 18道问答题)下的收益。但是,更小的窗口为决策有用性提供了更有力支持,因为它
表明,是会计信息真正使得投资者改变信念,从而改变证券报酬。
5.3.3 盈利水平与盈利变化
回顾一下鲍尔和布朗把盈利的信息含量定义为实际值与期望值之间的差异,这里的期望盈利 是根据与系统因素盈利相关的会计 系数估计得出,或者是根据上一年的实际盈利估计得出。
5.2.2节给出了对非期望盈利起做用的原因。
然而,在例3-1里,比尔·考雪丝用的是盈利水平。具体地说,盈利水平高就是利好消息(GN)。 于是,盈利的利好消息( GN)就有两种不同的构造:
高盈利水平,如例 3-1中;
高于期望值的盈利水平,如鲍尔和布朗的论文所述。
对于利空消息则相反。这两种构造都将导致投资者改变信念。但哪一个与当前或将来公司业 绩的联系更紧密呢?即哪一个具有更高的信息系统主要对角概率呢?
在确定性的理想条件下,答案是明显的(因为在确定性下没有非期望盈利)。回顾例 2-1中的 P.V.有限公司。在 t=1期P.V.的净收益为 17.36美元。奥尔森在 1991年指出公司在 t时刻的市场价值可 以这样表示:
Pt =
1 + Rf
Rf
NI t - Dt
(5-1)
= 1.10 ? 17.36 - 0
0.10
= 190.96
令t=1,这里, R =0.10是利息率,股利 D 为0。除了微小的舍入(凑整)误差,这与例 2-1中
f t
P.V.公司第 1期期末的市场价值 190.91是一致的。
我们也可以根据市场报酬来表示这种关系,把它除以公司公开价值:
R f =
Pt - Dt
t-1
-1 = 190.96 - 1 = 0.10
173.55
重要的是,由于 P 可由NI 表示,见式( 5-1),因此,净收益水平就可用来解释市场报酬。
t t
P = 1
f
[(1 + Rf )( NIt - Dt ) - at ] (5-2)
奥尔森指出,这种结果能沿用到非确定性下的理想条件情形。具体地说,
P = 1
[1.10( -23. - 0 ) + 50]
t 0.10
= 1
0.10
= 1
0.10
( -26.37 + 50)
23.63= 236.30
你也没有留邮箱~这个很多的~相信你也知道,发不下~
能源经济学的研究方向
5.2.2.1 数据库
根据该系统的开发需求,按照数据库的功能和作用将其分为风险查询类、风险评价类、系统管理类三大类(萨师煊等,2000)。主要数据见表5.5。
表5.5 海外油气与金属矿产开发风险管理系统的主要数据表
续表
5.2.2.2 数据仓库
油价数据来源于美国能源部(DOE)下属的能源信息署(EIA)网站、中石油(CNPC)网站和《华尔街日报》(WSJ)网站提供的油价数据,油价序列本身就是一个不规则的时间序列,油价数据具有以下几个特点。
(1)数据的一致性差
油价数据格式多样,存在数据冗余,主要体现在:使用的数据格式均不相同,并且各个子系统相对独立。在网站单独作用的情况下,一般都没有问题,但要将这些不同系统或不同时期的数据集中起来综合利用,就可能出现数据不齐全、不一致或重复的现象。
(2)数据存放的分散
油价数据来源多,缺乏统一管理,没有一种相应的网页数据自动化抓取操作实现数据的本地化操作过程。
(3)数据开发不充分
大容量数据导致对数据的开发利用不充分,缺乏对获取的数据如各分析机构制定的期货合约元数据进行各种深层次分析、综合、提炼、挖掘和展现的应用,因此很难对丰富的统计数据进行二次开发利用。
根据油价数据中所包含的油气产品种类、油气产品合约制定日期、油气产品的价格类型、不同市场下油气产品价格的差异等,能够加深对油价走势的了解。油价的这种与时间相关性、不可修改性,以及集成的性质,使得我们用多种角度对原始数据进行理解,并真实反映其特性,也让我们发现使用一种整合的技术对油价进行精确预测十分必要。
数据仓库的构建流程如图5.13所示由下至上逐步实现。
图5.13 数据仓库构建流程
1)数据源。
A.数据源的复杂性。数据分散在数据库管理系统、电子表格、电子邮件系统、电子文档甚至纸上。系统中要求集的3个数据源中,EIA 网站存储在网页上的油价相关更新较慢,虽然提供了各市场日、周、月、年的油价数据下载,但是下载完成之后的表格字段格式时常发生变化,这为实现自动获取数据并下载到本地自动入库的要求增加了难度;中石油网站数据除上述只显示3条数据之外,网站上会将访问流量过大的IP地址列入黑名单使其不能继续下载到本地进行保存,为这些数据建立统一的模型将会耗费很大精力。
B.数据的有效性。由于存在经验局限,如何处理数据的空值、不同时间间隔时间字段格式,入库时应注意的问题等,如果应用程序没有检验数据的有效性,会对数据多维显示产生极大影响,因此也归结为数据源数据质量问题。
C.数据的完整性。数据源上的数据并不那么明显或者容易获得。油价是高度敏感的数据,因此各个网站虽然提供了各个油品交易市场的日、月或年数据,但是完整性并不能充分保证,根据企业政策的不同,有时对要获得的数据,需花费大量精力。为此,要对不同的数据源进行建库,以保证所获数据的完整性。
2)数据处理。
高效的多维数据集展示离不开底层数据源数据的精确获取,或者叫做数据理解和数据清洗。于是系统在基于元数据获取、加工、入库和多维数据集展示上实现预期的要求。
A.ETL。该功能是整个油价数据仓库的核心之一,主要功能是按照事先定义的数据表对应关系从相关系统表中抽取数据(Extraction),经过数据清洗和转换(Transform),最终把正确的数据装载到数据仓库的源数据中(Load),作为以后应用的基础。
B.数据转换。该功能是在数据抽取过程中按照定义的规则转换数据,避免了数据在分析时的多样性,保证数据一致性。
C.数据集成。该功能主要是把油价信息数据仓库系统的源数据,按照事先定义的计算逻辑以主题的方式重新整合数据,并以新的数据结构形式存储。
3)数据存储。
星型模型(星型架构)是数据仓库开发中多维展现重要的逻辑结构,构成星型模型的几个重要特征是:维、度和属性,在实际应用中表示为事实表和维度表。在油价数据中,各市场的期现货价格表为数据仓库的事实表,油品类型、合约规定日期等为维度表。
油价数据仓库星型模型的设计方案如下:
A.事实表。数据库表中EIA的期现货价格表(包括日、周、月、年表)作为数据仓库中的事实表,根据不同时间维度构成多个星型模型,即星座模型。这些价格表中以市场编号、油气产品类型、期货合约日期、价格单位度量衡编号作为主键和外键与其他维度表相连,形成多维展示联动的基础,以油价数据和其他事实数据为记录数据,作为主要输出结果。
B.维度表。根据市场、油品、价格数据、度量衡和类型作为油气数据仓库中多维分析的角度和目标。
图5.14以EIA的日期货数据表作事实表为例,构建星型模型,其他不同时间维度的模型结构图与此图基本相同。
图5.14 以EIA数据为例的日期货价格星型模型
以星型模型设计为基础,完善数据存储中操作型数据存储(ODS)的原型设计,提供DB-DW之间中间层的数据环境,可实现操作型数据整合和各个系统之间的数据交换。
齐齐哈尔市地下水水质评价与污染预警
针对我国的能源研究现状,我们认为,我国未来的能源经济学研究大致应有以下几个方向:
——能源消费与我国经济增长的相关性。在Ramsey模型的框架下,在生产函数中引入能源要素,然后根据历年的资本、劳动、能源、物质、社会生产总值的变动计算经济的均衡增长路径。或者是建立计量模型,根据时间序列数据考察能源密度、劳动力密度与全要素生产率的相关关系,以及资本、劳动、物质和能源的替代弹性(包括中长期)的符号与大小。
——估计能源需求函数,建立能源需求的研究框架。考察影响需求的各个因素(包括经济周期的影响),根据历年电力、石油等能源的产量变化得到各种能源品消费组合的变动。
——根据我国能源定价体制,估计能源价格波动方程。1998年,国家对原油、成品油价格形成机制进行了重大改革,改变了单一定价,开始推行市场化定价模式,与国际接轨。影响油价的经济因素和政治因素也更加复杂了,我们需要关注的如:石油需求、替代品的价格、石油的预测和可开量、性能与储量、世界政治形势、石油的控制权、石油投资、各国及石油组织的垄断策略等等,也可以研究我国能源价格与世界能源价格的相关性和滞后性。
——研究能源行业的产业组织结构和供给效率。例如,研究能源消耗密度与工业结构的演进趋势、生产结构是否随着时间趋于更高的能源密度等,以及对于国内石油、电力、煤炭等垄断性的能源行业建立垄断竞争模型。
——分析能源冲击对宏观经济各变量的影响、价格波动导致的受益与损失。还有,研究能源消费对环境的冲击所导致的社会变化,以及进一步的能源立法。
——研究能源进口战略、替代战略与国家经济安全。利用石油期货市场等国际资本市场规避风险,保证国家石油安全。
——建立包含能源在内的可计算一般均衡模型,进行能源政策分析。目前国际上涉及能源的CGE模型主要是环境政策方面。我们可以在CGE模型中引入能源生产和能源消费,进而模拟分析能源政策对经济各部门的影响。
一、研究区概况
(一)自然地理与社会经济概况
研究区位于松嫩平原西部齐齐哈尔市内,嫩江东侧,北临富裕县,东接林甸和杜尔伯特蒙古族自治县,南部是泰来县。研究区地理坐标:东经123°53′~124°15′,北纬47°10 ′~47°24′,东西长27.39 km,南北宽26.32 km,总面积为720.9 km2,海拔高度一般在200~500 m 之间。地形以平原为主,地势呈马蹄型,东南两侧高、中间低,由北向南逐渐降低。齐齐哈尔市属寒温带大陆性季风气候,南部属温暖干旱农业气候区,中部属温和半干旱农业气候区,北部属温凉半湿润农业气候区。年平均气温在0.7~4.2℃之间,南北相差3.5℃左右。年降水量在400~550 mm 之间,年平均无霜期122~151 d。齐齐哈尔地区土壤主要有暗棕壤、黑土、黑钙土、草甸土、沼泽土、草甸碱土、砂土。齐齐哈尔市大部分土壤具有热量高、透性好、质地轻的特点。
齐齐哈尔市是以重型机械、冶金工业为主体的东北地区老工业基地之一,是黑龙江省第二大城市,具有包括化工、轻工、纺织、建材、食品、电子、医药等门类齐全的工业体系,是黑龙江省西部地区的政治、经济、科技、文化教育、商贸中心和重要的交通枢纽,全市辖7个区、1个市、8个县,人口561.1×104人(市区143.9×104人)。
(二)水文地质概况
齐齐哈尔市位于嫩江低平原,地貌上跨越冲积倾斜平原、冲积-河谷平原、冲积-湖积低平原3个地貌单元。水文地质条件较为复杂,地层由巨厚的白垩纪、新近纪陆相碎屑岩沉积物和第四纪砂、砂砾石为主的松散堆积物组成。
研究区第四系松散堆积物较厚,一般160~190 m。在40~60 m处普遍存在一层弱透水的亚粘土或亚砂土层,厚度一般小于7 m,将区内含水层分隔成水力特征有明显差异的上部潜水和下部承压水。上部潜水含水层厚度24.3~43.0 m,含水介质以砂砾石为主,次为中粗砂、中细砂,夹数层亚粘土、亚砂土透镜体,水位埋深2~5 m,水量丰富,单井涌水量大于2000 m3/d。下部承压水含水层较厚,中更新统含水层厚度一般70~85 m,含水介质为含砾中粗砂、砂砾石,下更新统含水层厚度一般20~50 m,含水介质为含砾中粗砂、中细砂。水位埋深3~5 m,水量较丰富,北部单井涌水量大于2000 m3/d,南部及东南部单井涌水量1200~2000 m3/d。
潜水主要补给来源为大气降水渗入补给、河水渗入补给、侧向径流补给及灌溉水回渗补给,主要排泄方式是人工开、蒸发、越流补给承压水。承压水的主要补给来源为上部潜水的越流补给、侧向径流补给,主要排泄方式为人工开和侧向径流排泄。
区内第四系潜水和承压水均为中性低矿化重碳酸型淡水。pH 值一般在6.6~8.36之间;TDS潜水为230~800 mg/L,承压水为140~380 mg/L;总硬度:潜水120~500 mg/L,承压水90~170 mg/L;水化学类型两者基本相同,均以HCO3-Ca、HCO3-Ca—Na、HCO3-Na—Ca型为主,其次为HCO3-Ca—Mg型水。由于潜水已经受到比较严重的污染,水化学类型变得比较复杂,在中心城区-大民屯-榆树屯一带形成了一种以含大量硝酸盐和氯化物为特征的污染水化学类型。另外,受原生环境影响,含水层中普遍有淤泥质亚粘土夹层,其淤泥质中有机质分解,形成还原环境,使介质中高价铁、锰还原成低价铁、锰,因此,地下水中铁、锰含量普遍较高,但含量年变化不大。
(三)地下水水质监测数据
本次研究水质监测数据主要来源于齐齐哈尔市地质环境监测站设置的地下水动态长观井1998~2002年枯水期的水质分析结果,水质监测点共31个,其中潜水14个、承压水17个(表13—14、表13—15)。监测的项目主要有pH、总硬度、氨氮、硝酸盐、亚硝酸盐、砷、汞、铬、铅、氟、镉、铁、锰、硫酸盐、氟化物、铜、锌、碘化物等。齐齐哈尔市地下水水质评价与污染预警系统,实现了对这些监测数据的增加、修改、删除、查询等基本管理功能,见图13—7。
表13—14 齐齐哈尔市地下水潜水水质监测资料统计表
表13—15 齐齐哈尔市地下水承压水水质监测资料统计表
(四)研究区空间信息
空间信息包括研究区地理底图、岩性分布图、地下水水质预警参数分区图、水源地及污染源分布图和土地利用现状图(见图13—8~图13—10)。
图13—7 齐齐哈尔地区地下水水质监测数据管理
图13—8 研究区空间信息界面
图13—9 研究区地形示意图
原比例尺1:50000
图13—10 研究区包气带岩性分布示意图
原比例尺1∶50000
二、齐齐哈尔市地下水水质评价
用国家标准、模糊综合评判、BP神经网络三种方法分别对每年的潜水和承压水进行评价。评价结果既有数据表格,也有等值线和等值面图。如图13—11是2002年潜水用BP神经网络评价方法得到的评价结果表格,图13—12是1998年潜水用国家标准综合评价得到的等值线图。
图13—11 2002年潜水BP神经网络评价结果
图13—12 1998年潜水国家标准综合评价等值线示意图
评价结果表明,齐齐哈尔市地下水水质具有以下特点:
(1)区内超标组分有:氨氮、硝酸盐、亚硝酸盐、砷、总硬度、氯化物、硫酸盐、铁、锰。
(2)“三氮”污染严重,14个潜水监测点中氨氮超标的有10个,最高含量2.35 mg/L(100号点2000年),超水质标准的8倍;硝酸盐超标的有7个,最高含量444.12 mg/L(228号点2002年),超水质标准的4倍;亚硝酸盐超标的有12个,最高含量1.680 mg/L(2号点2002年),超水质标准的24.6倍。
(3)局部地方总硬度超标(15、27、228号点),最高含量1043.67 mg/L(228号点2002年);局部地方砷超标(2、27、183号点),最高含量0.079 mg/L(27号点2001年)。
(4)区内地下水中铁、锰含量普遍较高,这主要是受原生环境控制,区内含水层中多有淤泥质亚粘土夹层,其淤泥质中有机质分解,形成还原环境,使介质中高价铁、锰还原成低价铁、锰物质,因此,地下水中铁、锰含量普遍较高,但历年变化不大。
三、齐齐哈尔市地下水水质预测
利用系统提供的灰色模型GM(1,1)和时间序列分析两种预测模型,可以对全部井的水质同时进行预测,也可以根据年份、点号、水期、水层等条件对特定井的水质进行预测。其中灰色模型GM(1,1)适合于对水质进行中短期预测,见图13—13。时间序列分析适合于对水质进行中长期预测,利用时间序列分析进行预测之前,除了要选择预测的点号,水期及含水层之外,还要为预测设置相应的权值。权值的设定范围理论上为0~1,但在应用中权值的设定应根据客观具体情况。如果相临年份之间的数据差异比较大时,设置较大的权值;反之,设置较小的权值。一般权值大小不宜超过0.3,见图13—14。
四、齐齐哈尔地区地下水污染风险评价
(一)含水层固有脆弱性评价
将含水层固有脆弱性评价的7个评价因子数据进行处理,绘成7张图件。
图13—13 灰色预测结果
图13—14 时间序列分析预测结果
(1)含水层埋深D
含水层埋深信息主要来自钻孔数据,利用克里金插值后得到含水层埋深空间分布图,然后按照评价标准表13—2重新分类。齐齐哈尔地区潜水含水层埋深一般在2~5 m,含水层埋深分级见图13—15。
(2)净补给量R
净补给量=降水入渗系数×多年平均有效降雨量(mm),齐齐哈尔地区的多年平均有效降雨量为419.9 mm,入渗系数按大小分为五个区,自西向东依次为0.30、0.05、0.23、0.18、0.07。将计算结果按照评价标准重新分类后得到净补给量分级图,见图13—16。
图13—15 含水层埋深分级示意图
图13—16 净补给量分级示意图
(3)含水层介质类型A
齐齐哈尔地区含水层岩性主要为砂砾石、细砂夹砾石、细砂、含砾中粗砂、含砾中细砂、含砾粗砂、中砂、粉细砂及含砾中砂土,其对应的特征值见表13—16。含水层介质类型分级见图13—17。
表13—16 含水层介质类型特征值
(4)土壤介质类型S
齐齐哈尔地区土壤介质类型主要有砂、亚砂土、亚粘土、黄土状亚粘土、杂填土。其对应的特征值见表13—17。含水层介质类型分级见图13—18。
表13—17 土壤介质类型分级标准
图13—17 含水层介质类型分级示意图
图13—18 土壤介质类型分级示意图
(5)地形坡度T
地形坡度是由高程点高程通过空间分析中的表面分析而计算出的坡度图,齐齐哈尔地区坡度分级见图13—19。
(6)包气带介质类型J
齐齐哈尔地区包气带介质类型主要有砂、亚砂土、黄土状亚粘土、亚粘土。其对应的特征值见表13—18。包气带介质类型分级见图13—20。
表13—18 包气带介质类型特征值
图13—19 地形坡度分级示意图
图13—20 包气带介质类型分级示意图
(7)含水层渗透系数C
含水层渗透系数划分为四个区,其分级标准参考表13—2,级别与脆弱性结论的对应关系见表13—19,分级见图13—21。
表13—19 级别与脆弱性结论的对应关系
将得到的各评价指标的分类图按下列公式加权叠加,得出齐齐哈尔地区含水层固有脆弱性分区图,见图13—22。
图13—21 含水层渗透系数分级示意图
图13—22 齐齐哈尔地区含水层固有脆弱性分区示意图
(二)污染源荷载风险评价
齐齐哈尔市污染源荷载风险评价是以2000年的资料进行的,该市2000年污染物排放总量为33 044.39 t,其中化学需氧量21 149.77 t,悬浮物11 576.81 t,石油类223.31 t,挥发酚59.46 t,氰化物103.39 t,六价铬2.04 t,砷7.30 t,硫化物15.05 t。主要排污区是龙沙区。
市区化肥农药使用情况(1999年),化肥施用量13 750 t,其中氮肥7563 t、钾肥2275 t、磷肥953 t、复合肥2959 t、农药使用量295 t。
工业固体废物与城市垃圾:固体废物主要集中在铁锋区和龙沙区。“九五”工业固体废物共15种,1335.58×104t,其中以粉煤灰、炉渣、冶炼废渣、危险废物、尾矿为主,计950.41×104t,占总量的71.31%。2000年各种固体废物如下:危险废物3.3206×104t,冶炼废渣9.30×104t,粉煤灰125.04×104t,炉渣54.01×104t,煤矸石0.01×104t,其他68.63×104t,合计260.31×104t。
2000年固体废物利用情况:危险废物2.68×104t,冶炼废渣7.58×104t,粉煤灰74.83×104t,炉渣53.85×104t,其他64.46×104t,合计203.41×104t。
“九五”末期,危险废物的数量由初期的8.878×104t下降到3.3206×104t,综合利用量2.68× 104t,利用率为80.71%,处置量0.6403×104t,处置率为99.99%,排放量0.000226×104t,仅占总量的0.0068%。危险废物的产生主要分布在富拉尔基、龙沙和碾子山区的机械电气、电子设备制造业和其他行业。区域分布高度集中,富拉尔基区占危险废物总量的99.86%。
2000年生活垃圾产生量71×104t,其中填埋处理21.7×104t,一般处理14.2×104t,简易处理35.1×104t。齐齐哈尔市废水排放量见表13—20。
表13—20 齐齐哈尔市废水排放量 (单位:104t)
齐齐哈尔北三区(铁锋区、龙沙区、建华区)共有红星、黎明、向阳生活垃圾处理厂三座,南山垃圾堆放场一座。其中黎明垃圾处理厂和南山垃圾堆放场占地面积大于30 000 m2,红星垃圾处理厂占地面积40 000 m2(3个池子)。向阳垃圾处理厂占地面积20 000 m2。红星、黎明、向阳三座垃圾无害化处理厂的卫生填埋区共计6个,总建筑面积121900 m2,容积1 463 000 m3。从2000年5月12日起红星、黎明、向阳三座无害化处理厂陆续建成投入使用,日处理生活垃圾800 t,到目前为止共处理中心城区生活垃圾近100×104t、吸排垃圾渗滤液12.5×104t、建筑垃圾150 000 m3。2003年10月1日医疗废物集中处置项目正式开工建设,建成投入使用后,中心城区医疗废物将实行无害化集中处置。
齐齐哈尔市城市氧化塘始建于10年,位于市中心区域西南17.5 km的旧江套处,氧化塘西侧靠嫩江左岸,尾部和嫩江接通。全部工程由明渠、氧化-储存塘、闸门、抽水泵站等构筑物组成,明渠全长6 km,渠与塘首结合部设泵站一座,塘首至塘尾泄水闸门全长9.3 km。
氧化塘北起新立屯黄沙滩,南至昂昂溪区大五福玛,占旧河道面积8 km2,平均水面约5.6 km2,丰水期近7 km2。它承担着城区60×104人口的城市混合污水的自理净化。齐齐哈尔氧化塘建塘初期日接纳污水10×104m3,经1986年改建,日接纳污水达25×104m3。1998年受嫩江大洪水破坏,1999年修复清淤后,日接纳污水能力达46×104m3。因此齐齐哈尔地区主要的污染源为红星、黎明、向阳生活垃圾处理厂、工人屯工业固体废弃物堆放场以及氧化塘和排污渠。系统运行后,得到的齐齐哈尔地区污染源荷载风险见图13—23。
(三)污染危害性评价
根据齐齐哈尔土地利用现状图,将居民所在地的地下水视为饮用,菜地、水田、农田等区域的地下水视为非饮用,其余地区为不使用。系统得到的齐齐哈尔地区污染危害性见图13—24。
(四)污染风险评价
将含水层固有脆弱性、污染源荷载风险、污染危害性评价结束后,将三者综合考虑叠加,得到齐齐哈尔地区污染风险图,具体评价方法见表13—10,通过计算机运算,评价结果见图13—25。其中“0”表示低风险,“1”表示中等风险,“2”表示高污染风险。
图13—23 齐齐哈尔地区污染源荷载风险示意图
图13—24 齐齐哈尔地区污染危害性示意图
五、齐齐哈尔地下水污染预警
地下水污染预警综合考虑了地下水水质现状、地下水水质变化趋势、地下水污染风险三方面的因素,共有45种可能出现的状态,通过计算机的分析计算可以确定不同的状态。预警的结果用警度来表达,“0”表示“无警”;“1”~“4”依次为“轻度预警”、“中度预警”、“重度预警”和“巨度预警”,结果表示地下水的污染的威胁程度越来越严重。
(一)单项预警
通过地下水水质评价发现,齐齐哈尔地区地下水中的氨氮、硝酸盐、亚硝酸盐、砷、总硬度、铁、锰超标现象比较严重,其中铁、锰主要受原生环境控制,历年变化不大。因此对于水质单因子预警可对氨氮、硝酸盐、砷进行预警。
以砷为例,首先从数据库中提取评价因子的浓度值,其次根据国家标准(GB/T14848—93)进行观测井中该因子的水质现状评价,通过空间插值得到该因子在研究区的空间分布图作为水质现状结果,见图13—26。然后利用Daniel的Spearman秩相关系数法分析观测井中该因子浓度多年变化趋势,空间插值后得到变化趋势分布图,见图13—27;最后由现状分布图、变化趋势图,污染风险图经计算机系统分析计算后获得预警结果图,见图13—28。
图13—25 齐齐哈尔地区污染风险示意图
图13—26 齐齐哈尔地区砷现状分布示意图
图13—27 齐齐哈尔地区砷变化趋势示意图
图13—28 齐齐哈尔地区砷污染预警结果示意图
研究区大部分区域砷浓度不超标,但西南部有三个观测井砷浓度达到五类水标准,而且多年监测结果表明有进一步恶化的趋势,因此该区域属于巨警区,污染十分严重。另外市区附近砷浓度符合三类水标准,历年无明显变化趋势,但污染风险高,因此该区域属于重警区,需重点关注。
氨氮、硝酸盐污染预警结果见图13—29,氨氮污染面积较小,硝酸盐污染十分严重,部分区域总硬度属于重警。
图13—29 齐齐哈尔地区氨氮、硝酸盐污染预警结果示意图
(二)综合预警
图13—30是齐齐哈尔地区地下水水质现状图,由图可以看出,研究区东部浅层地下水水质为三类水,研究区西部浅层地下水水质为四类水,已无法饮用。通过分析各监测井的水质污染综合指数变化趋势,顾甸车站附近的27号监测井的水质有所好转,位于查哈诺村的41号监测井的水质呈恶化趋势,其余监测井的水质无明显变化,见图13—31。图13—32为齐齐哈尔地区地下水污染预警图,由于该地区浅层地下水普遍已经遭受了污染,地下水中三氮的浓度达到了四类或五类水的标准,所以计算结果受地下水的现状影响较大,在市区及附近以重度、巨度预警为主。在市区东部预警以轻度、中度为主。
图13—30 齐齐哈尔地区地下水水质现状示意图
图13—31 齐齐哈尔地区地下水水质变化趋势分布示意图
图13—32 齐齐哈尔地区地下水污染预警结果示意图
实际上,地下水污染预警系统应该用于地下水未污染的地区,以起到预防污染的作用。而在齐齐哈尔地下水普遍遭受不同程度污染的地区,使用污染预警系统的作用和意义受到限制,发挥不出预警作用。
(三)齐齐哈尔地下水污染原因及防治措施
1.地下水污染原因
齐齐哈尔地区第四系潜水受到较严重的污染,主要污染原因有以下几点:
(1)地下水污染预警的巨警、重警区大部分靠近氧化塘、嫩江和劳动湖,地下水动态监测资料证实嫩江和劳动湖常年补给地下水,被污染塘、江、湖水直接渗透污染了第四系潜水。
(2)区内含水层埋深一般小于4.5 m,包气带岩性多为亚粘土、亚砂土和粉细砂,区内工业渗坑、井、生活污水井遍布,每年有11 720 t工业废水和生活污水通过渗坑、渗井渗入地下,造成了地下水污染。
(3)近郊区菜田和农业区长期大量施用农药、化肥,据统计每年使用化肥达17 531 t、农药178 t,这些化肥、农药灌溉水或雨水下渗污染地下水。
(4)工业废渣、生活垃圾等固体废物的堆放和土地填埋是地下水的重要的点污染源,据统计区内每年排放工业废渣186×104t,生活垃圾63 t。这些废渣和垃圾未经无害化处理,大多无防渗措施,在大气降水的淋滤作用下,可产生大量的含多种污染物质的渗滤液,这些渗滤液向下通过包气带可直接渗入含水层中,是造成第四系潜水污染的重要途径。
2.地下水污染防治措施
(1)严禁工业废水超标排放,提高氧化塘和排污染渠道的防渗标准,防止污水渗入地下。
(2)加速城市排水设施建设,完善排水系统,逐步取消城市生活污水渗井和简易厕所,严禁用渗坑(井)的形式排放工业废水。
(3)加快城市垃圾处理厂建设,提倡科学种田,合理施肥(可增加施肥次数,减少每次的施肥量),适量灌溉。
(4)搞好城市绿化,不仅可美化环境、调节气候,还能吸收土壤中的氨氮,减少对地下水的污染。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。